Amazon S3に保存した監査ログをAmazon Athenaアクションで検索する
以下の手順で、監査ログストリーミングでAmazon S3に保存した監査ログをAmazon Athenaアクションで検索できます。
事前準備
監査ログストリーミングに設定するバケットをAmazon S3で作成し、作成したバケットをベースマキナで監査ログのストリーミング先として設定します。
監査ログストリーミングの設定方法の詳細は監査ログのAmazon S3へのストリーミングをご参照ください。
1. Amazon Athenaデータソースを設定する
Amazon Athenaでデータベースを作成し、作成したデータベースをベースマキナのデータソースとして設定します。
データソースの設定方法の詳細はAmazon Athenaデータソースの設定をご参照ください。
2. Amazon Athenaでテーブルを作成する
Amazon Athenaで、2で作成したデータベースに1で作成したAmazon S3のバケットを使ってテーブルを作成します。
テーブルの例はテーブルの例をご参照ください。
テーブルの作成方法の詳細はAmazon AthenaのドキュメントのAthena でテーブルを作成する (opens in a new tab)をご参照ください。
3. Amazon Athenaアクションを設定する
1で設定したデータソースと、2で作成したテーブルに対してクエリを実行するSQL文を設定したアクションを作成します。
SELECT *
FROM your_table_name
-- 監査ログの種類を指定
WHERE audit_log_type = 'execute_action'
AND partition_date > '2025-01-01'
ORDER BY timestamp DESC
LIMIT 1000;アクションの設定方法の詳細はAmazon Athenaアクションの設定をご参照ください。
4. アクションを実行する
アクションを実行すると、設定したSQL文が実行され、監査ログのデータが取得できます。
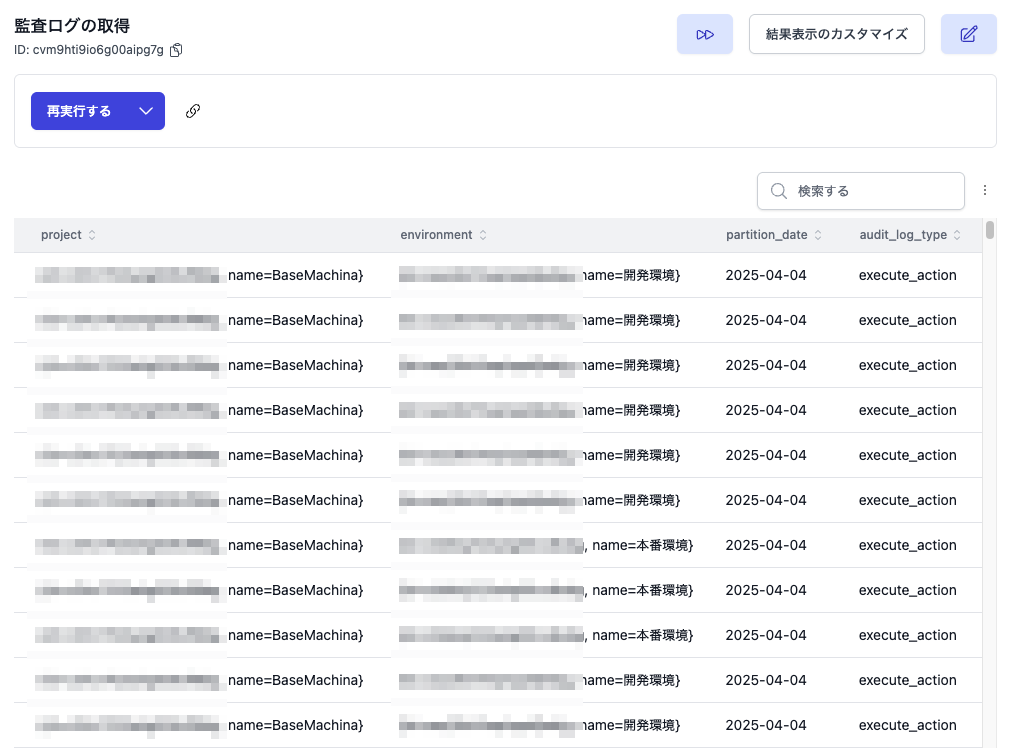
さらに{id=aaabbbcccdddeee, name=開発環境}のような文字列のAthenaのMAPやARRAY型の列の値は、
以下のようにCAST関数でJSON型に変換するとJavaScriptのオブジェクトや配列などに変換できます。
SELECT
CAST(action AS JSON) AS action,
CAST(environment AS JSON) AS environment
FROM your_table_name
WHERE audit_log_type = 'execute_action'
AND partition_date > '2025-01-01'
ORDER BY timestamp DESC
LIMIT 1000;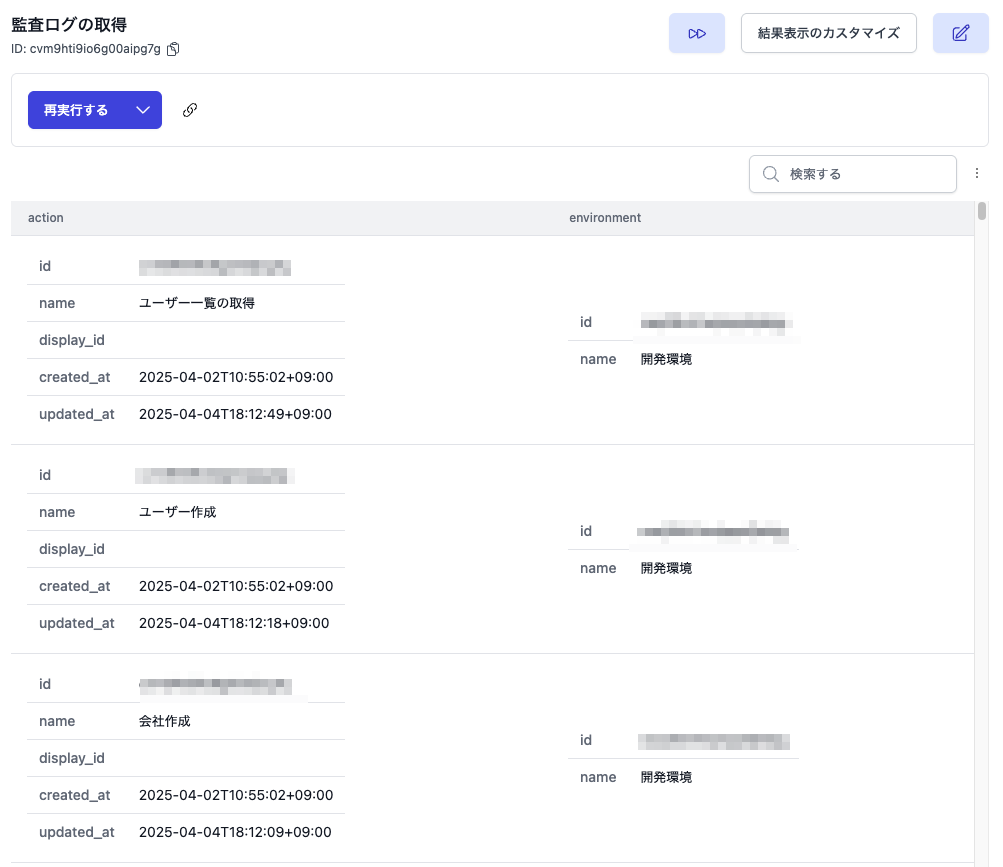
詳細はARRAY,ROW,MAP型の列の値をJavaScriptの配列やオブジェクトに変換するをご参照ください。
テーブルの例
以下は監査ログの形式に合わせたテーブルの例です。
-- your_bucket_nameには監査ログストリーミングに設定したAmazon S3のバケットの名前を指定してください。
-- your_database_nameには1で作成したデータベースの名前を指定してください。
-- your_table_nameは任意の名前を指定してください。
CREATE EXTERNAL TABLE IF NOT EXISTS `your_database_name`.`your_table_name` (
`timestamp` string,
`message` string,
`arguments` array<struct<name:string,value:string,type:string>>,
`bmrn` struct<resource:string,class:string,classid:string>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,
`tenant_id` string,
`client_ip` string,
`context_id` string,
`user` struct<id:string,name:string,email:string>,
`project` struct<id:string,name:string>,
`environment` struct<id:string,name:string>
)
PARTITIONED BY (
`partition_date` string,
`audit_log_type` string
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE',
'mapping' = 'TRUE'
)
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://your_bucket_name/'
TBLPROPERTIES (
'classification' = 'json',
'projection.enabled' = 'true',
'projection.partition_date.format' = 'yyyy-MM-dd',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'DAYS',
'projection.partition_date.type' = 'date',
'projection.partition_date.range' = '2023-01-01,NOW',
-- もしパフォーマンスが悪い場合は'injected'から'enum'への変更をお試しください
-- https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partition-projection-supported-types.html
'projection.audit_log_type.type' = 'injected',
'storage.location.template' = 's3://your_bucket_name/${partition_date}/${audit_log_type}'
);上記のテーブル定義は、保存先のパス形式が「日付 / 種別」(デフォルト)の場合の例です。「種別 / 日付」に変更している場合は、storage.location.templateを以下のように変更してください。
's3://your_bucket_name/${audit_log_type}/${partition_date}'パス形式の詳細は保存先のパス形式の変更をご参照ください。
監査ログの種類ごとの列の定義
以下は監査ログの種類(audit_log_type)ごとの列の定義です。
使用する監査ログの種類に合わせて必要な列の定義をテーブルに追加してご使用ください。
すべての操作で共通
`timestamp` string,
`message` string,
`tenant_id` string,
`client_ip` string,
`context_id` string,
`user` struct<id:string,name:string,email:string>,プロジェクト内のすべての操作で共通
`project` struct<id:string,name:string>環境内のすべての操作で共通
`environment` struct<id:string,name:string>execute_action
`arguments` array<struct<name:string,value:string,type:string>>,
`bmrn` struct<resource:string,class:string,classid:string>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,create_review_request
`arguments` array<struct<name:string,value:string,type:string>>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,
`review_setting` struct<id:string,name:string>,
`review_request` struct<id:string,description:string,created_at:string,expires_in:string>,approve_review_request,reject_review_request
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,
`review_request` struct<id:string,created_at:string,expires_in:string>,
`status` string,execute_action_with_review_request
`arguments` array<struct<name:string,value:string,type:string>>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,
`review_request` struct<id:string>,create_datasource,update_datasource,delete_datasource
`datasource` struct<id:string,name:string,typeId:string>,create_action,update_action
`bmrn` struct<resource:string,class:string,classid:string>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,
`review_setting` struct<id:string,name:string>,
`notification_settings` struct<on_success:struct<enabled:boolean,notification_method_id:string,mention_target_user_ids:array<string>>,on_error:struct<enabled:boolean,notification_method_id:string,mention_target_user_ids:array<string>>>,delete_action
`bmrn` struct<resource:string,class:string,classid:string>,
`action` struct<id:string,name:string,display_id:string,created_at:string,updated_at:string>,create_view,update_view,delete_view
`view` struct<id:string,name:string,display_id:string>,create_users,delete_users
`target_users` array<struct<id:string,name:string,email:string>>,update_user
`target_user` struct<id:string,name:string,email:string>,
`is_tenant_admin` boolean,create_project_users,delete_project_users
`project_users` array<struct<id:string,name:string,email:string>>,create_user_group,update_user_group,delete_user_group
`target_user_group` struct<id:string,name:string,admin_roles:array<string>>,assign_users_to_user_group
`users` array<struct<id:string,name:string,email:string>>,
`user_group` array<struct<id:string,name:string,admin_roles:array<string>>>,update_user_group_assignments
`user_group_assignments` array<struct<user:struct<id:string,name:string,email:string>,user_groups:array<struct<id:string,name:string,admin_roles:array<string>>>>>,create_review_setting,update_review_setting
`review_setting` struct<id:string,name:string>,
`environment_review_settings` array<struct<environment:struct<id:string,name:string>,self_approval_enabled:boolean,approver_execution_enabled:boolean,user_approval_conditions:array<struct<user:struct<id:string,name:string,email:string>>>,user_group_approval_conditions:array<struct<user_group:struct<id:string,name:string>,required_count:integer>>>>,delete_review_setting
`review_setting_id` string,update_environment_access_control
`target_environment` struct<id:string,name:string,access_control_enabled:boolean>,
`target_users` array<struct<id:string,name:string,email:string>>,
`target_user_groups` array<struct<id:string,name:string,admin_roles:array<string>>>,login_succeeded
すべての操作で共通の列の定義のみです。
connect_slack, disconnect_slack
`slack_workspace` struct<workspace_name:string>,create_slack_notification_method, update_slack_notification_method
`notification_method` struct<id:string,name:string>,
`environment_slack_notification_methods` array<struct<environment:struct<id:string,name:string>,channel_id:string>>,delete_notification_method
`notification_method` struct<id:string,name:string>,